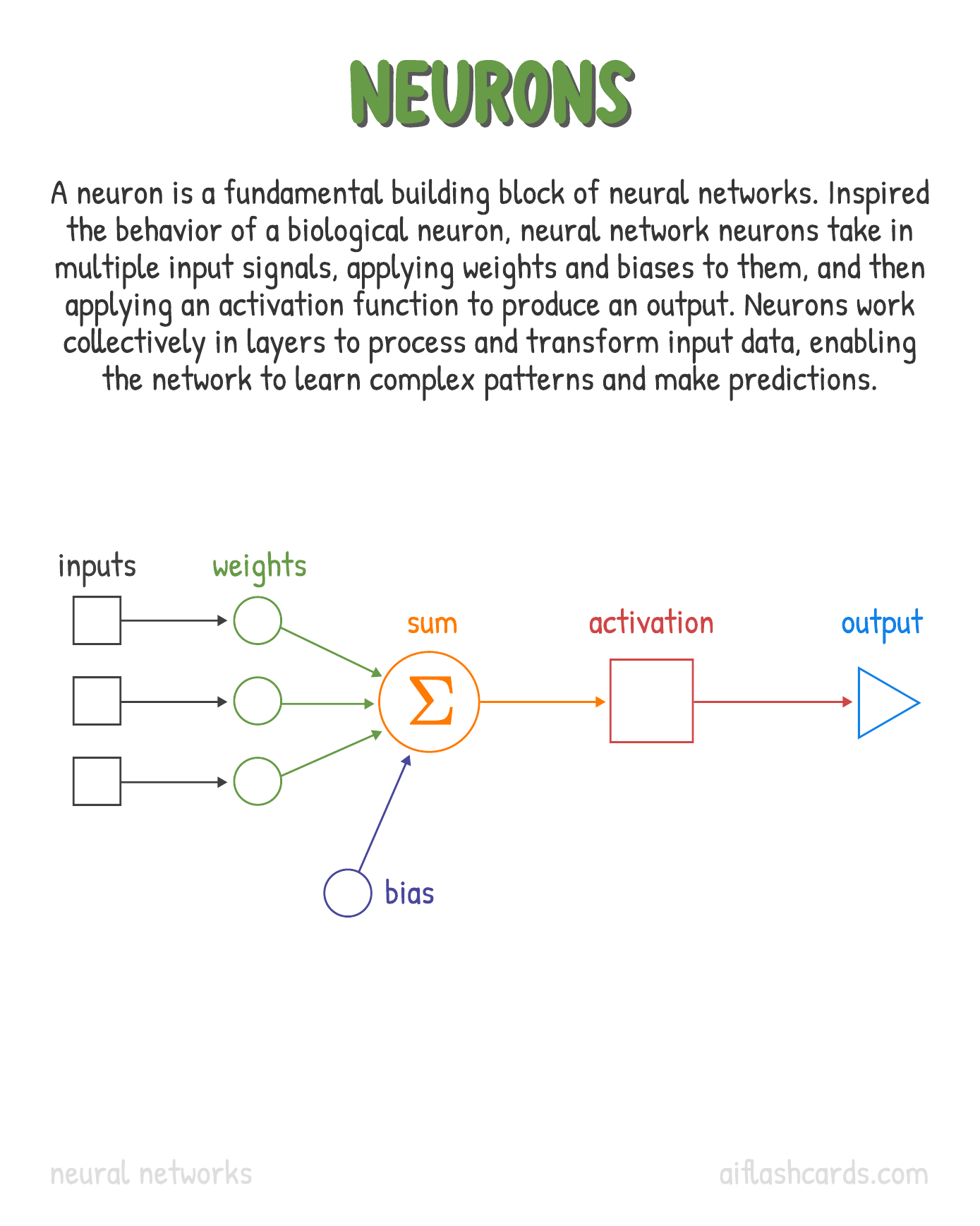
The perceptron was invented by Frank Rosenblatt is considered one of the foundational pieces of neural network structures. The output is viewed as a decision from the neuron and is usually propagated as an input to other neurons inside the neural network.
Perceptron
Math Intuition
We can imagine this as a set of inputs that averaged in weighted fashion.
If we imagine the input as representing the n-coordinates in a plane, then the multiplications scale/stretch/compress the plane, like a rubber sheet. (But do not fold it.)
If there were only 2 inputs, we could mentally picture this with a handkerchief.
More metaphorically, it seems like the neuron is consulting each of the inputs, asking for their opinion, and then making a decision by attaching different amounts of significance to each opinion.
So how does it work? Consider the interactive diagram below:
The coordinate axes are as shown X, Y, and Z
The grey and yellow points are the data we wish to classify into two categories, unsurprisingly “yellow” and grey”.
The Weight vector line is a vector of all the weights in the Perceptron.
Now, as per the point-normal form of an n-dimensional plane, the multiplication of the input data with the weight vector is like taking a vector dot product ( aka inner product) ! And: every point on the plane has a dot product of ZERO. See the purple vector which is normal to the Weight vector: its dot product with the Weight vector is zero.
Data points that are off this “normal plane” in either direction (above and below) will have dot-products which will be positive or negative depending upon the direction!
Hence we can use the dot-product POLARITY to decide if a point is above or below the plane defined by the Weight vector. Which is what is done in the threshold-based activation!
The bias \(b\) defines the POSITION of the plane; and the Weights define the direction. Together, they classify the points based on the Equation 1.
Try to move the slider to get an intuition of how the plane moves with the bias. Clearly, the bias is very influential in deciding the POLARITY of the dot-products. When it aligns with the purple vector (\(dot product = 0\)), it works best.
Why “Linear”?
Why are (almost) all operations linear operations in a NN?
We said that the weighted sums are a linear operation, but why is this so?
We wish to be able to set-up analytic functions for performance of the NN, and be able to differentiate them to be able to optimize them.
Non-linear blocks, such as threshold blocks/signum-function based slicers are not differentiable and we are unable to set up such analysis.
Let us try a simple single layer NN in R. We will use the R package neuralnet.
Show the Code
# Load the package# library(neuralnet)# Use iris# Create Training and Testing Datasetsdf_train<-iris%>%slice_sample(n =100)df_test<-iris%>%anti_join(df_train)head(iris)
Show the Code
# Create a simle Neural Netnn<-neuralnet(Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data =df_train, hidden =0,# act.fct = "logistic", # Sigmoid linear.output =TRUE)# TRUE to ignore activation function# str(nn)# Plotplot(nn)# Predictions# Predict <- compute(nn, df_test)# Predict# cat("Predicted values:\n")# print(Predict$net.result)## probability <- Predict$net.result# pred <- ifelse(probability > 0.5, 1, 0)# cat("Result in binary values:\n")# pred %>% as_tibble()